
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- go
- 싱글 스레드
- Python
- 노트북 추천
- 연산자
- Kotlin
- adapter
- blockchain
- javascript
- Java
- 자바
- var
- 자바스크립트
- 코틀린
- 배열
- Overloading
- Array
- 노트북
- golang
- HP
- 오버로딩
- ListView
- 파이썬
- 안드로이드
- 패널 교체
- node.js
- 함수
- Android
- ethereum
- js
- Today
- Total
Bbaktaeho
[DB/TSDB] 시계열 데이터베이스와 influxDB 본문
[DB/TSDB] 시계열 데이터베이스와 influxDB
Bbaktaeho 2022. 11. 29. 17:11들어가며
최근 데이터베이스의 여러 종류를 찾아보다가 시계열(time series) 데이터베이스를 처음 접하게 되었습니다.
가장 대표적인 데이터베이스로 influxDB가 있었는데요,

전체 데이터베이스에선 29위이지만 시계열 부분에선 1위입니다.
생소한 데이터베이스라 내가 앞으로 적용시킬 수 있는 부분이 있는지 조사해보도록 하겠습니다.
시계열 데이터베이스 (TSDB)
위키백과에서 시계열 데이터베이스는 하나 이상의 시간과 하나 이상의 값 쌍을 통해 시계열을 저장하고 서비스하는데 최적화된 데이터베이스라고 합니다. 여기서 시계열은 일정 시간 간격으로 배치된 데이터들의 수열을 뜻합니다.


시계열 데이터베이스는 시간이 지남에 따라 만들어진 데이터들로 구성되므로 시간 경과에 따른 변화를 추적하는데 용이하며 분석에 특화되어 있습니다. 따라서 실시간으로 쌓이는 대규모 데이터들을 처리할 수 있도록 고안되었습니다. 또한 대부분 최적화된 압축 알고리즘을 사용하여 비용도 최소화하고 있다고 합니다.
그리고 시계열 데이터베이스는 관계형 데이터베이스보다 데이터를 수집하는 속도가 느려지지 않고 빠른 처리 속도를 보인다고 하는데, 그 이유는 인덱싱으로 인해 대량의 데이터가 추가될 때 관계형 데이터베이스는 성능이 점점 저하되는데 시계열 데이터베이스는 시간을 기준으로 파티션을 나눠 저장하므로 데이터 수집 속도가 느려지지 않는다고 하네요.
(RDBMS에서도 파티셔닝 기능이 존재합니다)
국내에선 마크베이스에서 만든 시계열 데이터베이스가 있다고 합니다.
사용처
보통 시간에 따른 데이터의 요약 또는 통계 등과 같은 작업에 사용됩니다.
특히 주가 관련 데이터에 많이 사용된다고 하며 병원에서 환자의 상태, IoT에서 수집된 데이터를 저장하는 등 다양한 분야에서 사용되고 있습니다.
특징
- 시계열 데이터베이스는 실시간으로 시간에 따라 계속되는 데이터가 쌓이는 것에 특화된 데이터베이스
- 데이터가 끊임없이 적재될 수 있도록 쓰기 작업에 최적화
- 시간으로 누적된 데이터 속에서 변화를 감지하는데 적합
- 삭제, 수정에 대한 성능은 비교적 떨어질 수 있음
InfluxDB
시계열 데이터베이스를 대표하는 소프트웨어입니다.
Go언어로 개발되었으며 자칭 오픈소스 time series platform이라고 합니다.
데이터를 쿼리 및 저장을 위한 API를 포함하고 있으며 influxDB는 데이터들을 효율적으로 저장하고 압축하기 위해 time-structured merge tree(TSM), time series index(TSI) 파일에 저장됩니다. 자세한 내용은 링크에서 확인할 수 있습니다.
TICK Stack
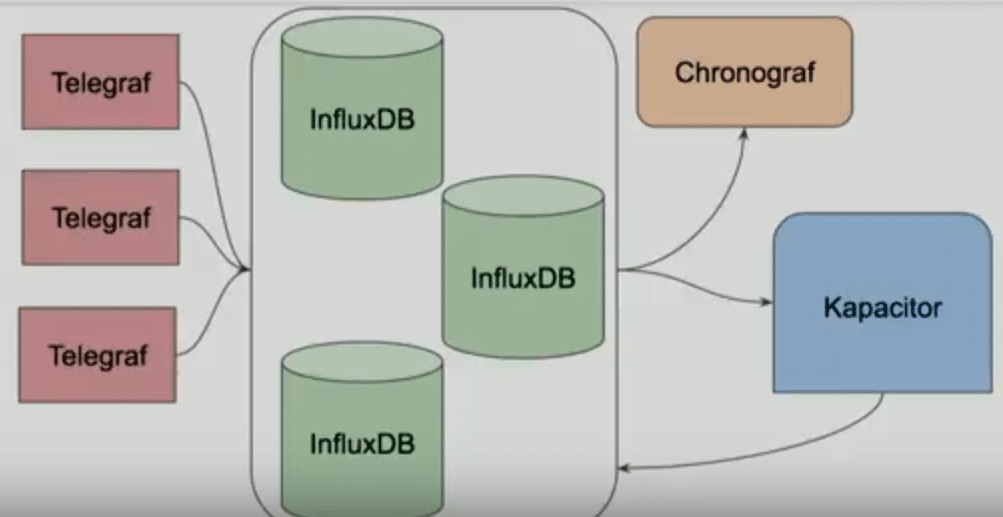
InfluxDB는 오픈 소스 프로젝트 세트가 있습니다. 이를 통틀어 TICK 스택이라고 합니다.
Telegraf는 메트릭 정보를 수집하는 에이전트입니다. Go binary로 되어있습니다.
InfluxDB는 디비 엔진입니다. Telegraf에서 오는 모든 메트릭이 전송됩니다.
Chronograf는 모든 데이터를 관리하고 볼 수 있는 대시보드입니다. 이 오픈 소스는 Grafana로 대체 가능합니다.
Kapacitor는 메트릭을 수신하고 발생하는 상황에 대해 사전 조치를 취하도록 구성할 수 있습니다.
사용처
대표적인 사용 사례로 IoT가 많습니다. 보통 실시간 집계에 사용되는데, 대용량의 메시지를 처리할 수 있는 메시지 브로커인 kafka와 함께 사용된다고 합니다.
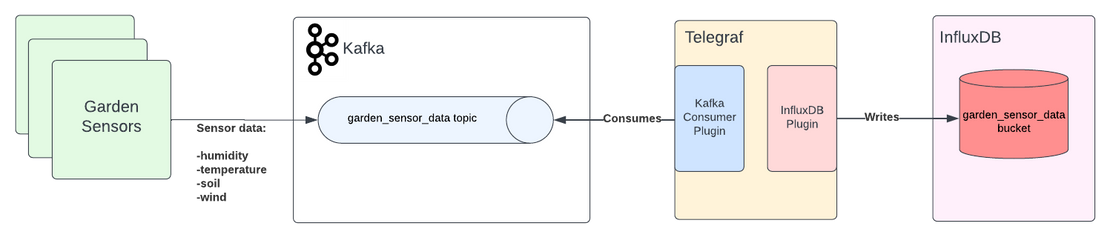
kafka는 메트릭 및 모니터링에 대한 쿼리가 없기 때문에 influxDB와 함께 사용될 수 있다고 합니다.
자세한 내용은 여기에서 확인하실 수 있습니다.
Data elements
influxDB에서 데이터 저장에 사용되는 요소들입니다. 공식 문서의 예제를 그대로 가져왔습니다.
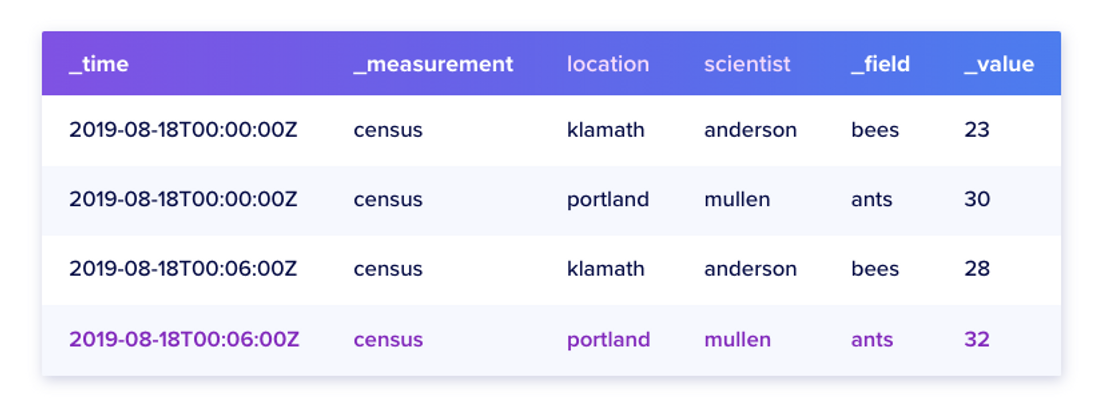
- timestamp
- 모든 데이터는 _time 컬럼이 존재
- nanosecond 포멧으로 기록
- measurement
- tags(location, scientist), fields, timestamps의 컨테이너 역할. 즉, 데이터를 설명하는 역할
- _measurement 컬럼은 측정할 이름을 보여주며 문자열 포맷
- fields
- _field 컬럼에 field key를 포함하며 _value 컬럼에 field value를 저장
- 필드는 인덱싱할 수 없음. 이유는 필드 값을 필터링하는 쿼리는 반드시 쿼리 조건과 일치하도록 모든 필드 값을 스캔할 수밖에 없기 때문
- field key
- field를 대표하는 문자열 데이터
- field value
- 문자열, floats, int, bool을 저장
- field set
timestamp, field key, field value의 키 벨류 쌍의 컬렉션census bees=23i,ants=30i 1566086400000000000 census bees=28i,ants=32i 1566086760000000000 ----------------- Field set
- tags
- 태그는 tag key, tag values를 포함하며 문자열과 메타데이터를 저장 (location, scientist)
- tag key
- location, scientist 정보가 컬럼이면서 tag key
- 문자열 길이 제한
- tag value
- klamath, portland 값들을 나타냄
- tag set
tag key, tag value의 키 벨류 쌍 field가 tag가 되고, tag가 field가 되도록 스키마를 재 정렬할 수 있으며 이러면 기존에 field set이 tag set이 되면서 인덱싱이 가능해지고 필드를 검색하려 할 때 성능이 좋아질 수 있음location = klamath, scientist = anderson location = portland, scientist = anderson location = klamath, scientist = mullen location = portland, scientist = mullen
- bucket schema
- measurement에 대한 명시적 스키마
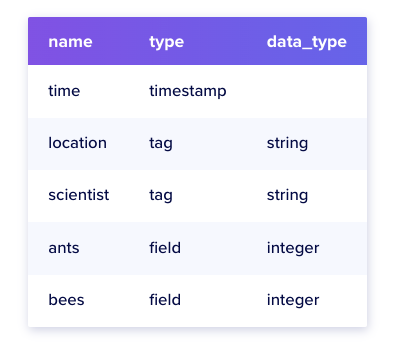
- series key
- series key는 measurement, tag set, field key 들로 구성

- series
- series는 timestamp, field value로 구성하며 series key를 위해 존재
# series key
census,location=klamath,scientist=anderson bees
# series
2019-08-18T00:00:00Z 23
2019-08-18T00:06:00Z 28
- point
- series key, field value, timestamp로 구성되어 있으며 단 하나만 존재
2019-08-18T00:00:00Z census ants 30 portland mullen
- bucket
- 모든 데이터는 bucket에 저장
- bucket은 데이터베이스 개념과 포인터의 보존 기간을 결합한 것
- organization
- 사용자의 그룹을 위한 작업 공간
- 사용자, 대시보드, 버킷 등의 모든 내용들이 속함
Design principles
- 성능 향상을 위해 데이터는 시간 오름차순으로 저장
- 읽기, 쓰기 성능을 높이기 위해 수정, 삭제에 엄격
- 읽기 요청을 우선시하며 쿼리 된 데이터에 영향을 미치는 모든 트랜잭션은 이후에 처리되며 일관성 보장
- 수집 속도가 높으면 최신 데이터가 포함되지 않을 수 있음
- 불연속 데이터를 잘 관리하기 위해 schemaless
- 데이터 세트가 개별 데이터보다 더 중요하기 때문에 전통적인 ID가 없음
- 충돌을 단순화하고 쓰기 성능을 높이기 위해 여러 번 전송된 데이터가 중복 데이터라고 가정
- 동일한 포인트는 두 번 저장되지 않음
- 포인터가 같으면 드물게 데이터를 덮어쓰기함
마치며
시계열 데이터베이스와 influxDB에 대해 알아봤습니다.
조사하게 된 이유는 블록체인의 데이터가 시계열로 쌓이고 있다 생각해서 블록체인 익스플로러 개발에 도입하고자 했습니다.
물론, 시계열 데이터로 볼 순 있으나 블록체인의 블록과 트랜잭션은 상당히 낮은 TPS를 보여주고 있으며 시간 기준으로 분석할 필요성이 없었고 단일 트랜잭션 조회성, 새로운 개선 제안으로 인한 block 및 tx이 추가될 수 있으므로 TSDB가 적합하지 않다고 판단되었습니다.
하지만 이번 조사를 통해 새로운 데이터베이스를 접했으며 추후 프로젝트에 넓은 시야로 임할 수 있을 것 같습니다.
References
https://byline.network/2020/02/27-76/
https://www.influxdata.com/what-is-time-series-data/
https://www.influxdata.com/blog/getting-started-apache-kafka-influxdb/
'컴퓨터 공학 (Computer Science) > 데이터베이스 (Database)' 카테고리의 다른 글
| [DB] PostgreSQL Large Table 최적화하기 (34) | 2024.07.24 |
|---|---|
| [DB/DocumentDB] 도큐먼트 데이터베이스와 MongoDB (2) | 2022.12.14 |

