
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- Overloading
- Python
- golang
- 연산자
- Java
- 코틀린
- node.js
- 자바스크립트
- javascript
- go
- js
- 배열
- 싱글 스레드
- Kotlin
- 패널 교체
- HP
- var
- as?
- adapter
- 자바
- 리스트 뷰
- Android
- 노트북
- 오버로딩
- 함수
- 안드로이드
- 노트북 추천
- ListView
- Array
- 파이썬
- Today
- Total
Bbaktaeho
[DB/DocumentDB] 도큐먼트 데이터베이스와 MongoDB 본문
[DB/DocumentDB] 도큐먼트 데이터베이스와 MongoDB
Bbaktaeho 2022. 12. 14. 17:27들어가며
방대한 양의 데이터가 생성되면서 기존의 데이터베이스들의 데이터를 쪼개서 저장하게 되었습니다.
여기서 기존 데이터베이스들은 관계형 데이터베이스를 의미하며 이들은 태생적으로 분산 처리에 어려움이 있었습니다.
이로 인해 새로운 NoSQL이라는 DBMS들이 개발되었고 많은 기업들에서 도입하기 시작되었다고 하네요.

NoSQL 중에서 서비스의 주축 데이터베이스로 가장 많이 선택되는 게 DocumentDB입니다.
가장 사용량이 많은 MongoDB를 중심으로 공식 문서를 통해 DocumentDB를 알아보도록 하겠습니다.
Document database (Document-oriented database)

도큐먼트 데이터베이스는 도큐먼트 지향 데이터베이스로 불리기도 합니다.
도큐먼트 데이터베이스는 스키마가 없는 데이터의 구성이 특징입니다.
Document
도큐먼트는 일반적으로 하나의 오브젝트나 관련 메타데이터에 대한 정보를 저장합니다.
도큐먼트는 field-value 쌍의 데이터를 저장합니다. 배열, 숫자, 문자열, 구조체 등의 다양한 값을 저장할 수 있습니다. JSON, BSON 그리고 XML 포맷을 저장할 수 있습니다.
배열을 허용함으로써 복잡한 계층 관계를 하나의 레코드로 표현할 수 있게 됩니다.
Collection
컬렉션은 도큐먼트의 그룹입니다.
컬렉션은 일반적으로 비슷한 콘텐츠를 가지고 있는 도큐먼트들을 저장합니다.
컬렉션의 모든 도큐먼트들이 같은 필드를 가지고 있는 것은 아닙니다. 왜냐하면 도큐먼트 데이터베이스는 유연한 스키마이기 때문입니다.
도큐먼트 데이터베이스에서 주요 기능은?
- Document model: 가장 인기 있는 언어와 매핑이 가능해서 빠른 개발이 가능
- Flexible schema: 하나의 컬렉션에 존재하는 도큐먼트들은 동일한 필드를 가지지 않아도 됨
- Distributed and resilient: 도큐먼트 데이터베이스는 replication을 통해 resiliency를 제공
관계형 데이터베이스와의 차이점은?
3가지 핵심 차이점이 있습니다.
1. 직관적인 데이터 모델
코드에서 객체로 매핑이 가능하므로 자연스러운 작업이 가능합니다. 테이블과 데이터 간 분해, 비용이 비싼 조인 또는 별도의 ORM 레이어와 통합할 필요가 없습니다. 함께 액세스 되는 데이터는 함께 저장되어 개발자들은 적은 코드를 작성하고 엔드 유저는 더 높은 퍼포먼스를 얻을 수 있습니다.
2. JSON 문서
json 문서는 가볍고 언어에 독립적이며 사람이 읽기 좋습니다.
도큐먼트는 다른 데이터 모델의 상위 집합이므로 개발자는 애플리케이션에 필요한 방식으로 데이터를 구조화할 수 있습니다.
3. 스키마의 유연함
도큐먼트의 스키마는 동적이며 자체 설명도 가능해서 개발자들은 데이터베이스를 pre-define 할 필요가 없습니다.
필드는 도큐먼트마다 다를 수 있습니다. 개발자들은 구조를 언제나 수정할 수 있고 위험한 스키마 마이그레이션을 피할 수 있습니다.
테이블보다 도큐먼트가 얼마나 더 쉬울까?
아래 도큐먼트는 User의 도큐먼트와 테이블의 예시입니다. (모두 공식 문서의 예제입니다.)
-- User의 도큐먼트 --
{
"_id": 1,
"first_name": "Tom",
"email": "tom@example.com",
"cell": "765-555-5555",
"likes": [
"fashion",
"spas",
"shopping"
],
"businesses": [
{
"name": "Entertainment 1080",
"partner": "Jean",
"status": "Bankrupt",
"date_founded": {
"$date": "2012-05-19T04:00:00Z"
}
},
{
"name": "Swag for Tweens",
"date_founded": {
"$date": "2012-11-01T04:00:00Z"
}
}
]
}
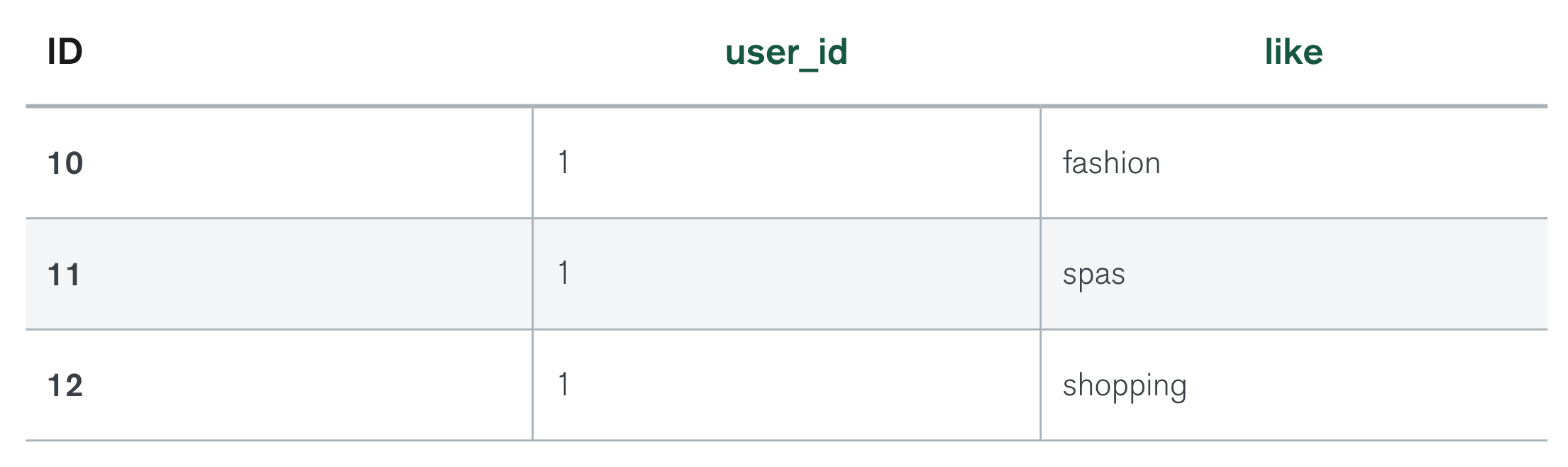
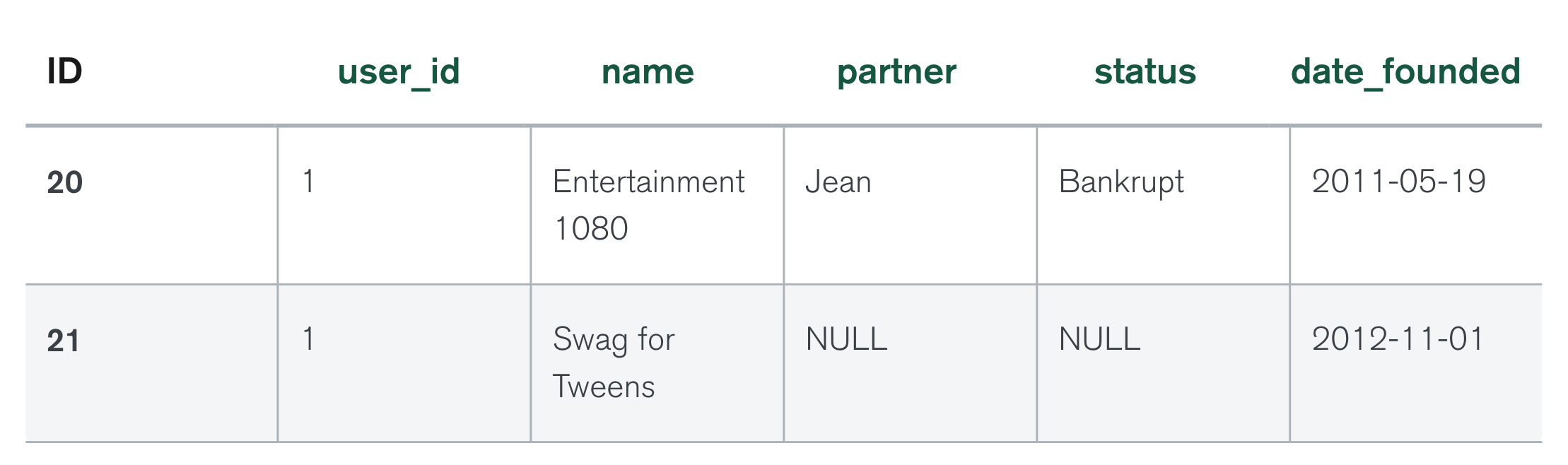
개발자들은 도큐먼트가 테이블보다 더 쉽고 더 직관적이라는 것을 알게 됩니다.
개발자는 관련 데이터를 저장하거나 검색할 때 여러 테이블에 수동으로 분리하는 것에 대해 걱정할 필요가 없습니다. 또한 데이터를 다루기 위해 ORM을 사용하지 않아도 됩니다. 대신에 그들의 애플리케이션에 즉시 데이터를 사용할 수 있습니다.
특징 정리
- 레코드들은 균일한 구조를 가질 필요가 없음. 즉, 레코드들은 컬럼이 다를 수 있음
- 개별 컬럼의 값 타입은 레코드마다 다를 수 있음
- 컬럼들은 여러 값을 가질 수 있음
- 레코드들은 중첩된 구조를 가질 수 있음
도큐먼트 스토어는 JSON처럼 앱에서 즉시 처리할 수 있는 표기법을 사용합니다.
물론 JSON 문서는 key-value 또는 관계형 디비에서 pure text로 저장될 수 있습니다. 그러나 디비의 클라이언트 측에서 별도 처리가 필요하며 도큐먼트 데이터베이스에서 제공하는 기능(보조 인덱스)을 사용할 수 없다는 단점이 있습니다.
장점
- 개발자를 위해 빠르고 쉽게 작업할 수 있는 직관적인 데이터 모델
- 애플리케이션 요구 사항이 변경됨에 따라 데이터 모델을 발전시킬 수 있는 유연한 스키마
- 수평적 확장이 가능
이러한 이점들 때문에 도큐먼트 데이터베이스가 다양한 유스 케이스와 산업체에서 사용될 수 있는 general-purpose DB입니다. 도큐먼트 데이터베이스는 NoSQL 데이터베이스로 고려되며, 고정된 row와 columns으로 저장되는 대신에 유연한 문서로 사용됩니다. 또한 테이블 형식의 대안으로 가장 인기 있는 데이터베이스입니다.
MongoDB
앞서 도큐먼트 데이터베이스에 대해 알아봤습니다.
MongoDB는 도큐먼트 데이터베이스를 대표하는 프로덕트로서 함께 알아보도록 하겠습니다.
MongoDB는 C++ 언어로 개발되었으며 오픈소스입니다.
MongoDB는 3.2부터 기본 엔진으로 WiredTiger Storage Engine을 채택했습니다.
WiredTiger 엔진은 Hazard-Pointer, Skip-List, MVCC, 압축 등의 기능을 가지고 있습니다.
https://github.com/mongodb/mongo
특징
도큐먼트 데이터베이스의 특징을 그대로 가지고 있습니다.
따라서 MongoDB만의 몇 가지만 알아보겠습니다.
ObjectId
MongoDB에 저장된 모든 도큐먼트는 _id 키를 가집니다. 기본형은 ObjectId이며 어떤 데이터형이든 상관이 없습니다.
여러 서버에 걸쳐 자동으로 증가하는 기본 키를 동기화하는 작업은 어렵고 시간이 많이 걸립니다. MongoDB는 분산 데이터베이스로 설계되었기 때문에 현재 시간(타임스탬프)이 사용되는 ObjectId를 만들었습니다.
ObjectId는 12 Byte로 구성되며 첫 4 Byte는 타임스탬프, 5 Byte는 랜덤, 마지막 3 Byte 랜덤 카운터로 서로 다른 시스템에서 충돌하는 id를 생성하지 않도록 합니다.
ObjectId는 1초에 약 1600만 개까지 생성이 가능하다고 합니다.
Cursor
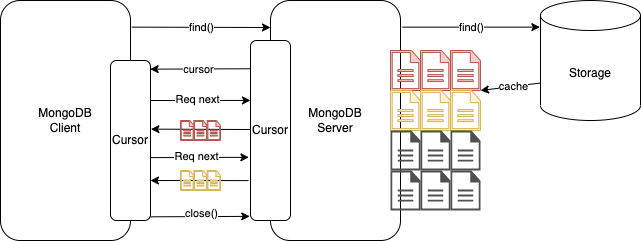
클라이언트에서의 Cursor와 클라이언트의 Cursor가 나타내는 디비 서버 Cursor가 있습니다.
클라이언트 측의 Cursor는 결과를 건너뛰거나, 결과 수를 제한하거나 정렬하는 다양한 연산을 수행합니다.
iterator 인터페이스를 구현했으며 next를 이용해 다른 결과를 가져오게 됩니다.
while (cursor.hasNext()) {
cursor.next(); // 요청
...
}
cursor.close(); // 해제Cursor가 만들어질 때 즉시 데이터베이스에 쿼리 하지 않고 결과를 요청하는 쿼리를 보낼 때까지 기다립니다.
서버 측에서 보면 Cursor는 메모리와 리소스를 점유합니다. 클라이언트에서 종료하거나 더 이상 결과가 없다면 서버 측의 Cursor가 점유한 리소스를 해제합니다.
그러나 여전히 Cursor가 유효하다면 timeout에 의해 종료됩니다.
BSON (Binary JSON)
{"hello": "world"} →
\x16\x00\x00\x00 // total document size
\x02 // 0x02 = type String
hello\x00 // field name
\x06\x00\x00\x00world\x00 // field value
\x00 // 0x00 = type EOO ('end of object')
{"BSON": ["awesome", 5.05, 1986]} →
\x31\x00\x00\x00
\x04BSON\x00
\x26\x00\x00\x00
\x02\x30\x00\x08\x00\x00\x00awesome\x00
\x01\x31\x00\x33\x33\x33\x33\x33\x33\x14\x40
\x10\x32\x00\xc2\x07\x00\x00
\x00
\x00MongoDB는 storage에 BSON 형태로 데이터를 저장합니다.
BSON은 BYTE, INT32, INT64, DOUBLE 타입을 이용해서 데이터를 저장하며 텍스트를 저장하는 비용보다 훨씬 저렴하게 저장할 수 있습니다. 이런 공간적인 절약은 데이터를 파일로 저장하거나 전송할 때 가볍고 효율적으로 처리할 수 있습니다.
분산된 Read, Write Operation
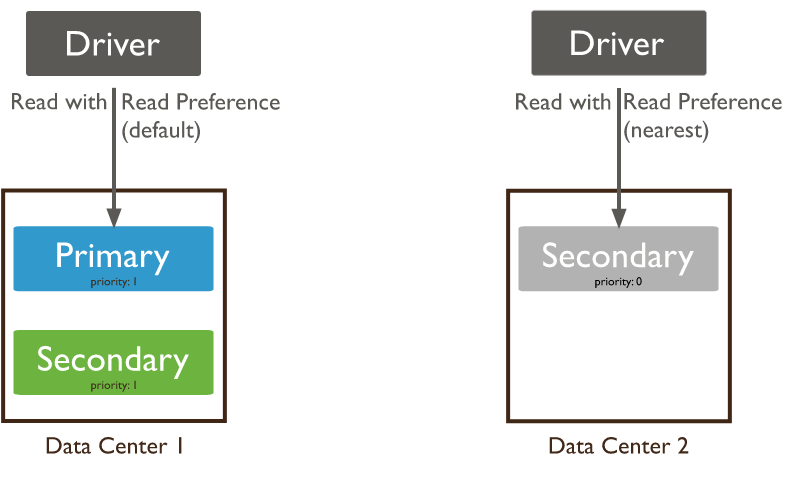
기본적으로 클라이언트는 replica set의 primary에서 데이터를 읽습니다. 하지만 데이터를 읽을 때 다른 멤버에서 읽을 수 있도록 명시할 수 있습니다. 이는 쿼리를 분산해서 처리량을 개선합니다.
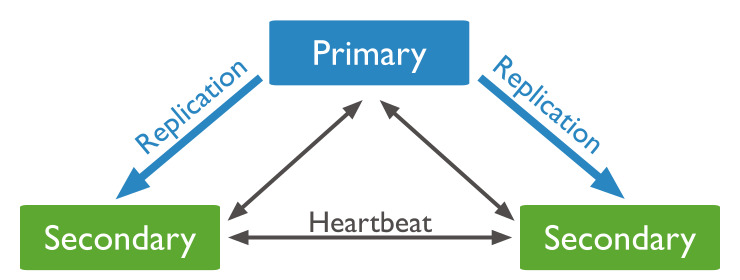
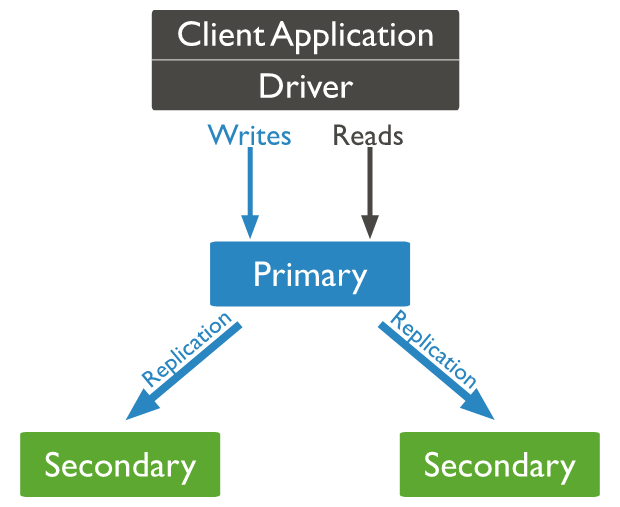
Primary는 replica-set 모든 쓰기 작업을 수행하는 멤버이고 Secondary는 Primary 복사본을 받아 관리합니다.
Primary는 쓰기 작업 로그를 기록하며 Secondary 멤버들이 로그를 지속적으로 복제하면서 관리합니다.
Shared Cluster
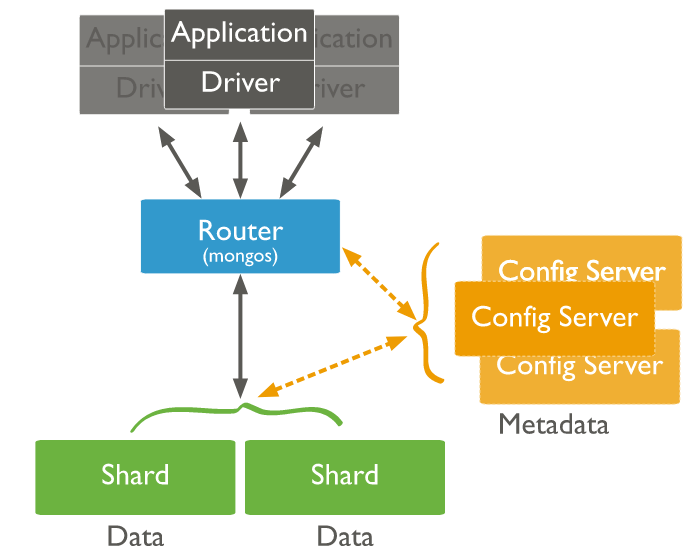
MongoDB는 분산 확장을 고려하여 설계되었습니다. 도큐먼트를 자동으로 재분배하고 애플리케이션의 요청을 올바른 장비에 라우팅함으로써 클러스터 내 데이터 양과 부하를 조절할 수 있다고 합니다.
Best Design Principle
- 불가피한 이유가 없는 한 임베딩을 선호하라 (소규모의 one-to-many)
- 참조로 구성할 경우 개체를 포함하지 않고 _id 리스트를 저장 (one-to-many)
- 가능한 조인을 피하되 더 나은 디자인을 제공할 수 있다면 두려워하지 말라
- 배열은 제한 없이 커지지 않게 컬렉션을 분리하자 (one-to-squilions)
스키마를 SQL처럼 디자인하면 MongoDB의 이점을 많이 잃게 된다고 합니다.
RDBMS 정규화의 핵심은 데이터를 테이블로 분할하여 데이터를 복제하지 않는 것입니다. 하지만 MongoDB를 설계할 때 중요한 것은 애플리케이션에 잘 맞는 스키마를 설계하는 것입니다.
또한 MongoDB는 16MB의 문서 크기 제한이 있으므로 단일 문서에 많은 데이터를 포함하면 안 됩니다.
주관적인 생각
각 DBMS안에서 지원하지 않는 기능이라 하더라도 서드파티 도구들을 사용하여 결국 같은 방향으로 진화하고 있습니다.
그 중에 MongoDB는 자체적으로 수평적 확장에 특화되었다고 볼 수 있을 것 같습니다.
규모가 작고, 새롭게 시작되는 프로젝트라면 충분히 고려하여 좋은 결정을 내리는 게 좋지만, 기존의 대규모 데이터를 다루는 프로젝트나 기업에선 데이터베이스는 매우 보수적인 기술이라 각 DBMS의 특징을 정확히 파악하고 단점을 보완할 수 있는 다양한 방법들을 부가적으로 사용하는 게 좋다고 생각합니다.
References
https://db-engines.com/en/ranking/document+store
https://www.mongodb.com/document-databases
https://www.mongodb.com/collateral/mongodb-multi-document-acid-transactions
https://www.mongodb.com/developer/products/mongodb/mongodb-schema-design-best-practices/
https://www.mongodb.com/docs/manual/core/distributed-queries/
'컴퓨터 공학 (Computer Science) > 데이터베이스 (Database)' 카테고리의 다른 글
| [DB] PostgreSQL Large Table 최적화하기 (34) | 2024.07.24 |
|---|---|
| [DB/TSDB] 시계열 데이터베이스와 influxDB (4) | 2022.11.29 |

