
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- ListView
- HP
- 자바스크립트
- 자바
- node.js
- javascript
- golang
- Python
- 연산자
- 코틀린
- Array
- Kotlin
- 패널 교체
- Overloading
- js
- 오버로딩
- Java
- 노트북 추천
- 안드로이드
- adapter
- 노트북
- 함수
- ethereum
- go
- 파이썬
- blockchain
- 배열
- Android
- var
- 싱글 스레드
- Today
- Total
Bbaktaeho
[DB] PostgreSQL Large Table 최적화하기 본문
[DB] PostgreSQL Large Table 최적화하기
Bbaktaeho 2024. 7. 24. 23:06개요
특정 블록체인 데이터를 인덱싱하기 위해 재단에서 제공하는 오픈소스 인덱서를 사용 중이었다. 인덱서는 Rust로 구현되어 있으며 PostgreSQL에 데이터를 인덱싱한다.
인덱서는 프로세싱 기준마다 서로 다른 프로세서로 분리되며 서로 의존 없이 배포가 가능하다.
모든 프로세서를 구동했을 때 약 70개의 테이블에 데이터를 적재하고 있었고 테이블은 모두 단일 테이블이었다.
점점 증가하는 블록체인의 데이터 때문에 테이블은 매우 무거워졌으며 row 개수도 100억 개가 넘는 테이블도 존재했다.
PostgreSQL의 특징 중 VACUUM 이라는 중요한 특징이 있다.
보통 자동으로 해당 작업을 진행하면서 데이터베이스 팽창을 막고 쿼리 계획에 이점을 제공한다.
하지만 테이블이 커지면서 VACUUM 자체의 성능도 나빠지기 시작했다.
+----+----------------------------------------------------+--------+------+---------------------------------------------------------+
|pid |runtime |usename |state |query |
+----+----------------------------------------------------+--------+--------------------+------+------------------------------------+
|6450|0 years 0 mons 0 days 1 hours 52 mins 4.721775 secs |null |active|autovacuum: VACUUM public.xxx (to prevent wraparound) |
|6457|0 years 0 mons 0 days 1 hours 51 mins 59.408857 secs|null |active|autovacuum: VACUUM public.xxxxx (to prevent wraparound) |
|8033|0 years 0 mons 0 days 1 hours 33 mins 43.169177 secs|null |active|autovacuum: VACUUM public.xxxxxx (to prevent wraparound) |
+----+----------------------------------------------------+--------+--------------------+------+------------------------------------+또한 커져가는 테이블로 인해 upsert 성능이 느려졌으며 튜닝하기 위한 index 생성도 어려워졌다. 하필 블록체인에서 여러 행사가 많아지면서 수많은 트랜잭션이 생겼다. (블록체인 트랜잭션 기준으로 약 5700 TPS 이상 지속적으로 발생)
인덱서는 블록체인 트랜잭션에서 여러 파생 데이터로 프로세싱하여 데이터를 인덱싱한다. 즉, 1초에 수많은 데이터가 적재되는 셈이다.
특정 트랜잭션 기준으로 여러 테이블에 파생된 row의 개수를 확인해 보니 16 개 정도 생성됐다. 데이터베이스 기준으로 봤을 때 생성되는 rows의 개수는 다음과 같다.
1초에 생성되는 rows 수 = 5700 x 16 = 91,200
때문에 인덱서가 잘 따라오기 위해선 데이터베이스 서버 스케일업이 불가피했다.
이러한 문제가 지속되니 빠른 속도로 운영 비용이 증가했다.

이를 해결하기 위해서 테이블 파티셔닝과 index 튜닝, cluster 등의 튜닝 작업을 진행해야 했다.
이 글은 작업을 진행하면서 겪은 문제에 대해 삽질 과정을 공유하려고 한다.
Large Table Partitioning
데이터베이스 서버의 사양에 따라 테이블이 크다는 기준은 모두 다를 것이다. 나 역시 기준을 모른다.
여기에서 얘기하는 Large도 답을 내릴 수 없다고 한다. workload, 하드웨어 등에 의존적이기 때문이다.
하지만 하나 확실한 건 단일 테이블에 증가하는 데이터를 받기엔 잠재적인 성능 저하를 일으킬 수 있다. upsert, select 모두 마찬가지다.
PostgreSQL은 언제 파티셔닝 하면 좋을지 문서를 통해서 알아봤다.
These benefits will normally be worthwhile only when a table would otherwise be very large. The exact point at which a table will benefit from partitioning depends on the application, although a rule of thumb is that the size of the table should exceed the physical memory of the database server.
참고: PostgreSQL 공식 문서
PostgreSQL은 서버 메모리보다 테이블이 클 경우 테이블 파티셔닝을 권장한다.
만약 데이터베이스 서버의 메모리 사양이 32 GB 일 때 32 GB 보다 큰 테이블은 파티셔닝을 하는 게 경험적으로 좋다고 말하고 있다.
또한 테이블을 분할해 두면 전체 테이블을 스캔하는 대신 더 작은 집합만 스캔해도 되므로 성능 향상에 도움이 되고 분할된 테이블들을 서로 다른 디스크 공간에 배치하면서 확장성까지 향상하는데 도움을 준다.
테이블 관리에도 큰 도움을 준다.
예를 들어 한 달 전까지 데이터를 보관하는 정책이 있을 때 한 달 단위의 시계열로 파티셔닝 되어있다면 정책을 준수하는데 매우 효과적이다.
PostgreSQL에서 DELETE는 용량 확보를 할 수 없으므로 VACUUM FULL 을 수동으로 실행하거나, DROP TABLE을 해야 하는데 이들은 테이블 lock 그 이상의 문제를 야기할 수 있어서 시도조차 할 수 없다.
마지막으로 성능 튜닝을 위해서도 좋다.
보통 쿼리 성능을 위해 index를 생성하는데 index를 생성할 때 테이블이 한 개라면 write를 하지 못하므로 CREATE INDEX CONCURRENTLY로 생성해야 하지만 많은 제약이 따르며 테이블이 크니 오래 걸린다.
Table Size & Rows
작업이 필요한 테이블이 테이블 파티셔닝이 필요한지 확인이 필요하다.
그래서 테이블의 크기와 row 개수를 확인해 봤다.
-- 테이블 크기
select
table_name,
pg_size_pretty(pg_total_relation_size(quote_ident(table_name))) as total_size,
pg_size_pretty(pg_relation_size(quote_ident(table_name))) as table_size,
pg_total_relation_size(quote_ident(table_name))
from information_schema.tables
where table_schema = 'public' and is_insertable_into = 'YES' and table_type != 'VIEW'
order by 4 desc;
-- 결과
+-----------------------------------------------------+
|table_name |total_size|table_size|
+-----------------------------------------------------+
|.............................. |4785 GB |3269 GB |
|.............................. |3957 GB |1349 GB |
|.............................. |3182 GB |1230 GB |
|.............................. |2619 GB |2176 GB |
|.............................. |2529 GB |2022 GB |
|.............................. |2256 GB |1330 GB |
|.............................. |2096 GB |1743 GB |
|.............................. |1847 GB |735 GB |
|.............................. |1785 GB |1100 GB |
|.............................. |1553 GB |1233 GB |
|.............................. |1333 GB |800 GB |
|.............................. |1185 GB |919 GB |
|.............................. |660 GB |392 GB |
|.............................. |435 GB |264 GB |
|.............................. |162 GB |117 GB |
|.............................. |112 GB |73 GB |
|.............................. |101 GB |83 GB |
|.............................. |89 GB |65 GB |
|.............................. |68 GB |26 GB |
|.............................. |53 GB |39 GB |
|.............................. |49 GB |32 GB |
|.............................. |45 GB |21 GB |
|.............................. |43 GB |20 GB |
|.............................. |40 GB |10 GB |
|.............................. |28 GB |21 GB |
|.............................. |27 GB |10 GB |
|.............................. |26 GB |13 GB |
|.............................. |7401 MB |4121 MB |
|.............................. |6990 MB |3786 MB |
|.............................. |6036 MB |3718 MB |
...-- 테이블 row 개수 추정치
DO $$
DECLARE
rec TEXT;
res bigint;
BEGIN
FOR rec IN
SELECT table_name
FROM information_schema.tables where table_schema = 'public' and is_insertable_into = 'YES' and table_type != 'VIEW'
LOOP
EXECUTE format('SELECT reltuples::bigint AS estimate FROM pg_class WHERE relname = %L', rec) INTO res;
IF res > 0 THEN
RAISE NOTICE '% %', to_char(res, 'fm00000000000'), rec;
END IF;
END LOOP;
END $$;
-- 결과 (따로 정렬함)
table_name |estimate |
+---------------------------+-----------+
|.................. |19911690240|
|.................. |11979251712|
|.................. |05961646080|
|.................. |05899252224|
|.................. |05769236992|
|.................. |05603352576|
|.................. |05187501056|
|.................. |05182718464|
|.................. |04616607232|
|.................. |04606320128|
|.................. |04498319872|
|.................. |04351470592|
|.................. |01397714432|
|.................. |00413145024|
|.................. |00300619616|100 GB가 넘는 테이블이 여럿 있었으며 몇십 GB 테이블들도 수두룩했다.
또한 추정치이긴 하지만 row 개수도 10억 개가 넘는 테이블 혹은 100억이 넘는 테이블도 있었다.
테이블이 너무 커서 정확한 count를 확인하기는 어려웠다.
Table Partitioning
이제 large 테이블에 대해서 파티셔닝을 진행해야 한다.
기존 테이블에 파티셔닝을 진행할 때는 새로운 테이블에서 진행할 수밖에 없다.
동일한 테이블 이름으로 하고 싶어서 같은 데이터베이스의 새로운 스키마에 테이블을 생성하고 마이그레이션 하는 방식을 선택했다.
기존 테이블은 public 스키마에 있으며 새로 생성한 스키마는 temp 로 지정했다.
create schema temp;설명 전에 편의상 테이블을 별칭으로 부르겠다.
파티셔닝이 필요한 테이블은 public 스키마에 있으며 편의 상 테이블 이름은 source 또는 public.source 로 설명할 것이며 파티셔닝 된 테이블은 dest 또는 temp.dest로 표기하겠다.
실시간 데이터 동기화
인덱서는 쉬지 않고 데이터를 만들고 데이터베이스에 저장한다.
때문에 파티셔닝 작업을 하면서 최신 데이터에 대한 누락이 발생할 수도 있다. 따라서 실시간 데이터를 동기화하는 live 테이블도 생성했다.
이 테이블은 기존 테이블과 동일한 컬럼과 PK를 가진 테이블로 구성한다.
CREATE TABLE IF NOT EXISTS temp.dest_live
(
...,
CONSTRAINT ... primary key (...)
)그런 다음 실제 인덱서가 바라보는 테이블에 trigger를 등록한다.
CREATE OR REPLACE FUNCTION public.<함수이름>()
RETURNS TRIGGER AS $$
BEGIN
INSERT INTO temp.dest_live VALUES (NEW.*);
RETURN NULL;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER <트리거이름>
AFTER INSERT OR UPDATE ON public.source
FOR EACH ROW
EXECUTE FUNCTION public.<함수이름>();이제 dest_live 테이블에 실시간으로 데이터가 저장될 것이다.
Partition 테이블 생성
하나의 테이블을 물리적으로 나눌 때 어떻게 분할할지 조건이 필요하다.
파티셔닝을 진행하려고 했던 테이블들이 모두 historical data가 적재되는 테이블로서 시간 정보가 조건이 될 수 있었다.
CREATE TABLE IF NOT EXISTS temp.dest
(
...,
transaction_timestamp timestamp not null,
...,
CONSTRAINT ... primary key (...)
) PARTITION BY RANGE (transaction_timestamp);하지만 여기서 문제가 있다.
PostgreSQL에서는 제약 조건에 해당하지 않는 column이 partition 조건이 될 수 없는 것이다.
아래는 에러 메세지의 내용이다.
[0A000] ERROR: unique constraint on partitioned table must include all partitioning columns
Detail: PRIMARY KEY constraint on table "dest" lacks column "transaction_timestamp" which is part of the partition key.해당 에러는 PostgreSQL의 Partitioning limitations 중 하나임을 문서를 통해 확인할 수 있었다.
To create a unique or primary key constraint on a partitioned table, the partition keys must not include any expressions or function calls and the constraint's columns must include all of the partition key columns. This limitation exists because the individual indexes making up the constraint can only directly enforce uniqueness within their own partitions; therefore, the partition structure itself must guarantee that there are not duplicates in different partitions.
참고: PostgreSQL 공식 문서
하지만 방법이 없는 것은 아니다.
부모 테이블이 아닌 파티셔닝 된 자식 테이블에 대해서 PK를 생성하면 간단하게 해결된다.
대신, 중복이 발생할 수 있으므로 파티셔닝 테이블을 설계할 때 데이터에 대해 완벽히 이해하고 넘어가야 한다.
이제 테이블 파티셔닝을 진행하면 된다.
좀 더 찾아보니 파티션 테이블 관리나 생성을 쉽게 해 주는 pg_partman extension을 사용하기로 했다.
설치하는 법은 다음과 같다.
CREATE SCHEMA partman;
CREATE EXTENSION pg_partman WITH SCHEMA partman;partman 스키마를 생성해서 설치하면 필요한 함수들이 partman 스키마 안에서 생성되어 스키마가 지저분해지지 않는다.
또한 partman은 dynamic partition 테이블을 손쉽게 생성하는 방법도 제공한다.
쿼리를 통해서 버전도 확인할 수 있다.
SELECT * FROM pg_available_extensions where name = 'pg_partman';현재 내가 사용하는 버전은 v4.7.3 이다. 버전마다 사용법 차이가 있으니 꼭 doc를 확인해야 한다.
설치가 완료되면 create_parent 함수를 통해서 파티션 테이블을 생성할 수 있다.
작업 순서는 다음과 같다.
1. 부모 테이블 생성
-- parent 테이블 생성
create table if not exists temp.dest
(
...
transaction_timestamp timestamp not null,
...
) PARTITION BY RANGE (transaction_timestamp);파티셔닝 조건 때문에 PK 생성은 하지 않았다.
2. template 테이블 생성
pg_partman template 기능을 통해 자식 테이블의 제약 조건이나 index 등을 편리하게 생성도 가능하다.
-- template 테이블 생성
create table temp.dest_template (LIKE temp.dest);
-- template 테이블에 제약 조건 추가
alter table temp.dest_template ADD PRIMARY KEY (...);부모 테이블에 생성하지 못했던 제약 조건은 template 테이블에다가 생성한다.
index도 생성할 수 있지만 마이그레이션 작업에서 성능 저하를 유발하므로 완료된 후에 생성한다.
또한 unlogged를 세팅해 줄 수도 있는데 만약 replication이 구축되어 있다면 WAL를 통해서 데이터를 캡처할 수 없으니 주의해야 한다. (필자도 unlogged로 진행하다가 한번 더 작업하게 되었다. unlogged가 확실히 빠르긴 하다)
3. 파티션 테이블 생성
-- partman을 통한 파티션 테이블 생성
select partman.create_parent(
'temp.dest',
'transaction_timestamp',
'native',
'1 month',
p_start_partition := '2022-09-01',
p_template_table := 'temp.dest_template',
p_premake := 12
);v4.7.3 버전에서 create_parent 시그니처는 다음과 같다.
자세한 내용은 참고 링크에서 확인 가능하다. (참고: https://github.com/pgpartman/pg_partman/blob/v4.7.3/doc/pg_partman.md)
create_parent(
p_parent_table text,
p_control text,
p_type text,
p_interval text,
p_constraint_cols text[] DEFAULT NULL,
p_premake int DEFAULT 4,
p_automatic_maintenance text DEFAULT 'on',
p_start_partition text DEFAULT NULL,
p_inherit_fk boolean DEFAULT true,
p_epoch text DEFAULT 'none',
p_upsert text DEFAULT '',
p_publications text[] DEFAULT NULL,
p_trigger_return_null boolean DEFAULT true,
p_template_table text DEFAULT NULL,
p_jobmon boolean DEFAULT true,
p_date_trunc_interval text DEFAULT NULL
) RETURNS boolean내가 생성한 parent 테이블을 토대로 설명하면,
temp.dest 테이블이 부모 테이블이며
transaction_timestamp 컬럼이 분할 기준이고
native 타입으로 지정하여 PostgreSQL의 native partitioning 타입을 사용하게 되고 (range, list)
파티셔닝은 1 month 단위로 생성되며
파티션 테이블의 시작은 2022-09-01 부터 시작하고
temp.dest_template 테이블을 템플릿 삼아 테이블들이 생성될 것이며
현재 날짜 기준으로 12 개의 테이블을 미리 생성하게 된다.
생성이 완료되면 아래 쿼리로 파티션 테이블을 확인할 수 있다.
SELECT inhrelid::regclass AS child
FROM pg_catalog.pg_inherits
WHERE inhparent = 'temp.dest'::regclass;대략 도식화 하면 다음과 같다.
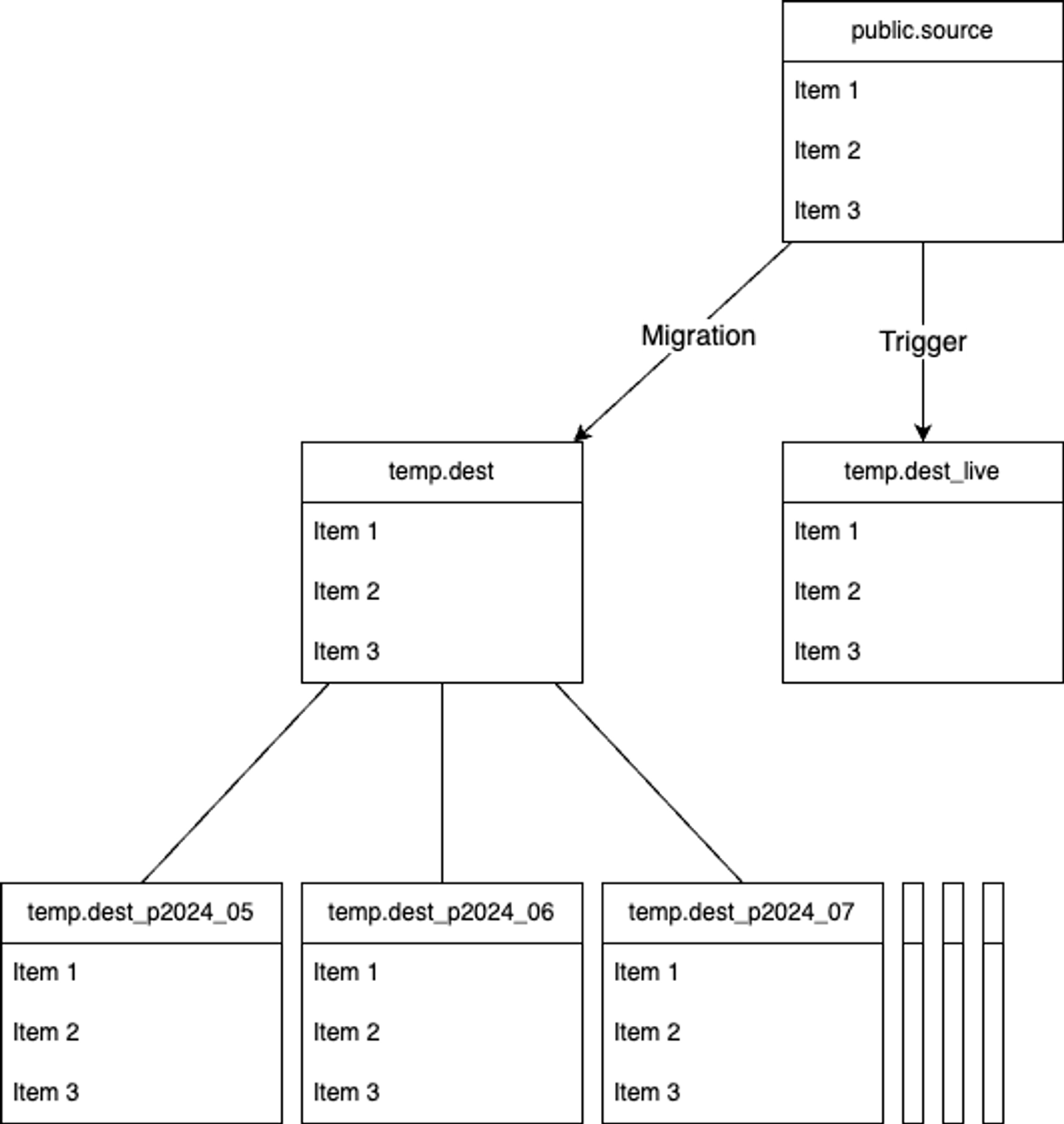
Migration
파티션 테이블을 생성했으니 이제 source에서 데이터를 옮겨와야 한다.
보통 insert into select 쿼리 한 번으로 마이그레이션 하는 방식이 많이 보여서 그대로 진행했었는데 끝날 기미가 안보였다.
빠르게 마이그레이션 할 수 없을까 고민하다가 작업하려는 source 테이블에서 inserted_at 컬럼에 index가 생성되어 있어서 이를 활용하기로 했다. 해당 테이블에 수정될 일도 없었으니 최적의 조건으로 판단했다.
방식은 inserted_at index에 범위를 잡고 병렬 insert를 하는 것이다.
오픈소스 인덱서를 구동한 시점부터 현재까지 시점을 보니 대략 3개월 정도였다. 그래서 inserted_at를 1일 단위로 쪼개어 병렬 insert 할 수 있도록 코드를 작성했다.
언어는 Go로 작성했으며 pgx 드라이버 라이브러리를 사용했다.
// 생략...
func worker(_ int, sqlCh chan string, finishCh chan<- struct{}) {
for sql := range sqlCh {
process(sql)
}
finishCh <- struct{}{}
}
func process(sql string) {
fmt.Printf("[process] start, %s\n", sql)
start := time.Now()
conn, err := pgDB.Conn()
if err != nil {
fmt.Printf("[process] %s, error=%s\n", sql, err.Error())
panic(err)
}
defer conn.Release()
ct, err := conn.Exec(context.Background(), sql)
if err != nil {
fmt.Printf("[process] %s, error=%s\n", sql, err.Error())
panic(err)
}
fmt.Printf("[process] finish, %s, count: %d, elapsed: %s\n", sql, ct.RowsAffected(), time.Since(start))
}
func main() {
sqlCh := make(chan string, workers)
finishCh := make(chan struct{}, workers)
go func() {
for i := 0; i < workers; i++ {
go worker(i, sqlCh, finishCh)
}
for d := start; d.Before(end); d = d.AddDate(0, 0, 1) {
sql := fmt.Sprintf(
"insert into %s (select * from %s WHERE %s >= '%s' and %s < '%s')",
destTable, sourceTable, timestampColumn, d.Format("2006-01-02"), timestampColumn, d.AddDate(0, 0, 1).Format("2006-01-02"),
)
sqlCh <- sql
}
close(sqlCh)
}()
finishCount := 0
for {
<-finishCh
finishCount++
if finishCount == workers {
return
}
}
}main 함수에서 생성하는 SQL 예시를 보면 다음과 같다.
insert into dest (select * from source WHERE inserted_at >= '2023-01-01' and inserted_at < '2023-01-02')이처럼 1일 단위의 SQL을 생성하여 worker 수에 맞게 postgres 세션이 활성화될 것이며 병렬로 처리되어 빠르게 마이그레이션 할 수 있었다. 또한 날짜별로 얼마나 많은 row가 생겨났는지 데이터 적재 추이를 알 수 있었다.
주의할 점은 많은 세션을 만들면 데이터베이스에 부하를 일으켜 문제가 발생할 수 있다. 데이터베이스 서버를 모니터링해 가며 적절한 worker 수를 지정하는 게 좋다.
사실 pg_partman 에서도 이와 비슷한 기능이 있다. partition_data_* 기능을 사용하면 쉽게 마이그레이션 할 수 있을 것이다.
주의할 점은 기본 값으로 데이터를 지울 것이다. 버전마다 차이가 있는 것으로 확인했는데 정확한 사용법을 숙지할 필요가 있다.
Index 생성
index 생성에는 write를 할 수 없도록 lock이 잡혀서 PostgreSQL은 CREATE INDEX CONCURRENTLY 를 통해 lock 없이 생성할 수 있다. 대신 더 많으 리소스가 필요하므로 느리게 생성된다.
하지만 dest 테이블들에는 그럴 일이 없으므로 CREATE INDEX 명령어로 진행했다.
미리 index를 생성할 수도 있지만 index가 매번 변경되어 마이그레이션 성능 저하를 불러온다. 따라서 마이그레이션이 완료된 후에 index 생성을 하기로 했다. 이 역시 테이블별로 parallel하게 세션을 생성하여 진행했다.
하지만 진행 중에 아래와 같은 에러가 발생했다.
could not write to file "파일이름": No space left on deviceindex를 생성할 때 메모리가 부족할 경우 임시 파일(PostgreSQL Temporary File)을 생성하게 된다.
이때 공간이 없어서 죽은 것이다.
PostgreSQL에서 임시 파일을 저장하는 공간은 temp_tablespace 다.
일단 temp space를 확인해 보니 internal storage를 붙인 장비가 아니라서 temp space가 비어있었다.
show temp_tablespaces;
-- 결과
+----------------+
|temp_tablespaces|
+----------------+
| |
+----------------+찾아본 방법은 config를 튜닝하는 법, instance를 변경하는 것이다.
하지만 instance를 변경하거나 work_mem 값을 올려서 각 세션별 메모리 사용 한계를 늘리는 것은 비용적인 문제나 OOM의 위험을 높일 수 있다.
참고로 work_mem은 세션별로 사용하는 메모리 공간을 늘리는 것으로 공용 메모리 공간으로 쓰이는 것이 아닌 세션 단위로 쓰이는 로컬 메모리의 값이다. PostgreSQL 커넥션 수가 많아지고 shared_buffers 메모리 공간을 쓰지 않는 쿼리(sort, join 등)가 많아질 때 OOM을 발생시킬 수 있다.
다시 돌아와서 근본적인 원인을 파악해 봤다.
원인은 테이블 크기다. 에러가 발생한 테이블의 크기를 확인해 보니 약 300 GB 정도였다.
PostgreSQL config를 튜닝보단 테이블을 파티셔닝 하는 게 더 좋은 판단이라고 생각해서 sub partitioning을 하기로 했다.
Sub Partitioning
월별로 파티셔닝 되어 있는 특정 파티션 테이블에 대해서 추가적인 파티셔닝을 진행해야 한다.
+-------------+
|dest_p2022_09|
|dest_p2022_10|
|dest_p2022_11|
|dest_p2022_12|
|dest_p2023_01|
|dest_p2023_02|
|dest_p2023_03|
|dest_p2023_04|
|dest_p2023_05|
|dest_p2023_06|
|dest_p2023_07|
|dest_p2023_08|
|dest_p2023_09|
|dest_p2023_10|
|dest_p2023_11|
|dest_p2023_12|
|dest_p2024_01|
|dest_p2024_02|
|dest_p2024_03|
|dest_p2024_04|
|dest_p2024_05| +----------------+
|dest_p2024_06| -----> |child |
|dest_p2024_07| +----------------+
|dest_p2024_08| |dest_p2024_06_01|
|dest_p2024_09| |dest_p2024_06_02|
|dest_p2024_10| |dest_p2024_06_03|
|dest_p2024_11| |dest_p2024_06_04|
|dest_p2024_12| |dest_p2024_06_05|
|dest_p2025_01| |dest_p2024_06_06|
|dest_p2025_02| |dest_p2024_06_07|
|dest_p2025_03| |dest_p2024_06_08|
|dest_p2025_04| | ... |
|dest_p2025_05|
|dest_p2025_06|
|dest_p2025_07|
+-------------+위 그림처럼 2024년 6월의 1일 데이터는 dest_p2024_06_01 테이블에 존재하게 된다.
파티셔닝 된 테이블에 파티셔닝을 sub partitioning 이라고 한다. (subpartition도 찾아볼 수 있었다)
pg_partman에도 sub partition 생성을 위한 기능이 존재한다.
create_sub_parent() 함수를 통해 생성할 수 있으며 이 함수는 이미 존재하는 파티션 세트의 하위 파티션을 생성한다.
(참고: pg_partman github)
하지만 이 기능을 사용하면 모든 파티션 테이블에 대해 하위 파티션이 생성된다. 즉, 굳이 sub partition이 필요 없는 테이블들까지 생성된다는 것이다. 이러면 테이블이 너무 많아진다.
또한 테스트해 보니 기존 데이터들이 제거되었다. 역시 정확한 사용법을 숙지해야 한다.
일단 모든 테이블에 대해서 만들 필요가 없기 때문에 직접 만들기로 했다.
작업 순서는 다음과 같다.
1. 1 day 기준으로 파티셔닝 할 parent 테이블 생성
-- parent 테이블 생성
create table if not exists temp.dest_p2024_06_day
(
...
transaction_timestamp timestamp not null,
...
) PARTITION BY RANGE (transaction_timestamp);
2. 파티션 테이블 생성
역시 pg_partman을 사용할 것이다.
template 테이블에 index를 생성해두지 않았기 때문에 기존걸 이용했다.
-- partman을 통한 파티션 테이블 생성
select partman.create_parent(
'temp.dest_p2024_06_day',
'transaction_timestamp',
'native',
'1 day',
p_start_partition := '2024-06-01',
p_template_table := 'temp.dest_template'
);현재 시점까지 파티션 테이블을 만들어내므로 2024년 6월이 아닌 테이블에 대해서는 수동 삭제했다.
3. Migration
시계열 기반의 index가 생성되지 않아서 insert into select 로 진행했다.
INSERT INTO dest_p2024_06_day SELECT * FROM deset_p2024_06;
4. Index 생성
위에서 작업한 것과 같이 index를 생성한다.
5. DETACH PARTITION
마이그레이션이 마무리되면 기존에 있던 2024년 6월 파티션 테이블은 DETACH 해야 한다.
ALTER TABLE dest DETACH PARTITION deset_p2024_06;이번 작업과 관련 없는 내용이지만 참고로 말씀드리면 파티션 테이블을 DROP 할 때 부모 테이블에 ACCESS EXCLUSIVE LOCK이 걸린다. 이를 피하기 위해서 DETACH를 해야 한다. (DETACH CONCURRENTLY 도 있다)
6. ATTACH PARTITION
1 day 파티션 테이블을 기존 월별 테이블에 붙인다.
여기서 ATTACH 할 때 우선적으로 해줄 작업이 있다.
PostgreSQL에서 ATTACH 작업을 진행할 때 암묵적으로 파티션 제약 조건을 확인한다.
CHECK 제약 조건이 없다면 ACCESS EXCLUSIVE LOCK 잡고서 모든 데이터를 풀스캔한다. SELECT까지 안되므로 스킵하기 위해 미리 만들어두는 것이 좋다고 한다.
하지만 CHECK 제약 조건 자체를 만드는 시간도 오래 걸리긴 했다.
ALTER TABLE dest_p2024_06_day ADD CONSTRAINT d_p2024_06 CHECK ( transaction_timestamp >= '2024-06-01' AND transaction_timestamp < '2024-07-01')
elapsed: 2h54m58.523125083s실제 테이블에서 걸린 시간은 약 3시간이다.
빈 테이블에 미리 만들어두는 것도 하나의 방법일 듯하다.
이제 ATTACH 한다.
> alter table temp.dest attach partition temp.dest_p2024_06_day for values from ('2024-06-01 00:00:00') TO ('2024-07-01 00:00:00')
[2024-07-12 21:52:28] completed in 651 ms확실히 ATTACH는 곧바로 끝난다.
ATTACH가 완료되었다면 CHECK 제약 조건을 제거한다.
It is recommended to drop the now-redundant CHECK constraint after the ATTACH PARTITION is complete. If the table being attached is itself a partitioned table, then each of its sub-partitions will be recursively locked and scanned until either a suitable CHECK constraint is encountered or the leaf partitions are reached.
참고: PostgreSQL 공식 문서
문서에서도 불필요한 CHECK가 sub partition에 도달할 때까지 재귀적으로 LOCK이 발생한다고 한다.
ALTER TABLE dest_p2024_06_day DROP CONSTRAINT d_p2024_06;
도식화해보자.
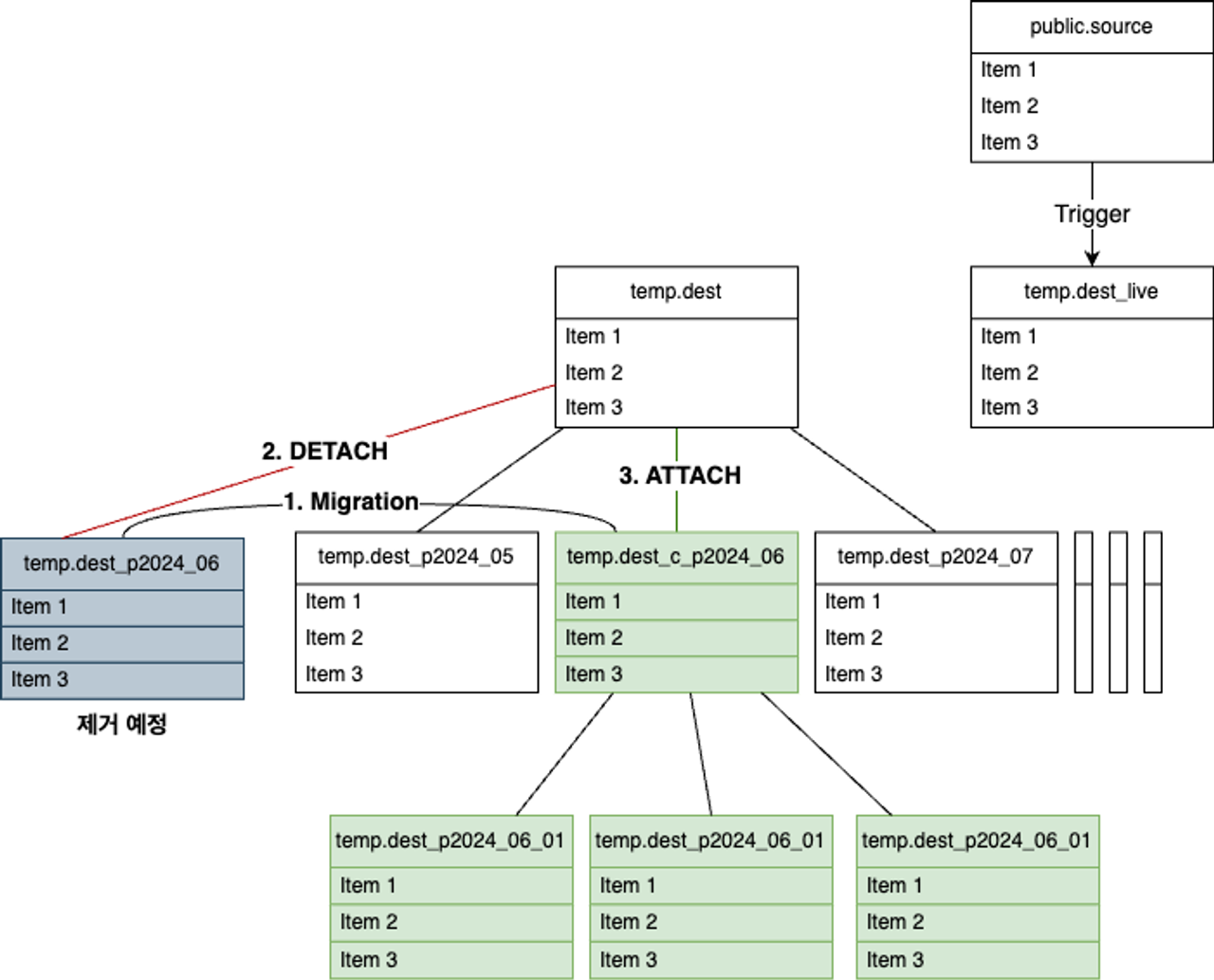
정리하면,
- 6월 테이블을 데이터를 1 day 파티션 테이블로 마이그레이션
- DETACH
- ATTACH
위와 같은 순서로 정리할 수 있다.
이로서 테이블이 하루 단위로 분할되어 가벼워졌고 index를 생성하는데 문제없었다.
Clustered Index
PostgreSQL에는 clustered index와 non-clustered index 두 가지 타입의 인덱스가 있다.
많은 RDBMS 에서 clustered index를 PK로 자동 설정하지만 PostgreSQL 에서는 원하는 index를 clustered index로 만들어 물리적인 정렬 순서를 index 순서로 바꿀 수 있다.
만약 테이블에 랜덤 access가 자주 발생하는 경우에는 중요하지 않을 수도 있다. 내가 작업하던 테이블은 시간 순서로 access되는 검색이 많아서 유의미한 결과를 가져올 것 같아 적용하기로 했다.
또한 과거에 적재되었던 테이블의 row도 변경되지 않기 때문에 미리 작업해 두기 좋았다.
자세한 내용은 여기에서 확인 가능하다.
Cluster Index 적용
시간 관련해서 범위 검색이 많을 것으로 예상하여 transaction_timestamp 컬럼으로 생성했던 index로 적용했다.
CLUSTER dest USING dest_transaction_timestamp_idx;작업 시간이 오래 걸리므로 테이블별로 처리하는 것이 좋을 수 있으며 굳이 생성하지 않아도 되므로 적용 전에 고민해 볼 필요가 있다.
Vacuuming
마지막으로 VACUUM ANALYSE 작업을 진행했다.
dead tuple 과 무관한 작업이었지만 VACUUM을 해야 하는 이유가 있다.
index scan과 관련 있는 visibility map 이나 쿼리 계획에서 사용되는 통계 정보를 업데이트하기 위함이다.
PostgreSQL 에서도 insert only 테이블의 autovacuum을 작동시키기 위해 autovacuum_vacuum_insert_scale_factor, autovacuum_vacuum_insert_threshold 등의 설정 값들이 존재한다.
자세한 내용은 여기에서 확인할 수 있다.
VACUUM ANALYSE
혹여나 autovacuum으로 처리되지 않을 것을 대비하여 모든 테이블에 대해 VACUUM 을 수동 실행했다.
VACUUM ANALYSE dest;이것 역시 파티셔닝이 되어있기 때문에 파티션 테이블별로 병렬 처리하여 빠르게 동작시킬 수 있다.
기존 테이블 교체
이로서 파티셔닝 작업은 마무리되었다.
한 가지 작업만 마무리되면 실제 쿼리를 받는 테이블과 바꿔치기가 가능하다.
바로 live 테이블 마이그레이션 작업이다. 해당 테이블은 데이터 누락을 방지하기 위해 처음 생성했던 테이블이다.
데이터 누락 방지
live 테이블에 있던 데이터를 모두 dest 테이블로 이동시키기 전에 source 테이블에서 dest 테이블로 데이터를 sync 할 수 있도록 트리거를 하나 더 생성해줘야 한다.
작업 순서는 다음과 같다.
- source → dest trigger 추가
- source → deset_live trigger 제거
- dest_live → dest 마이그레이션
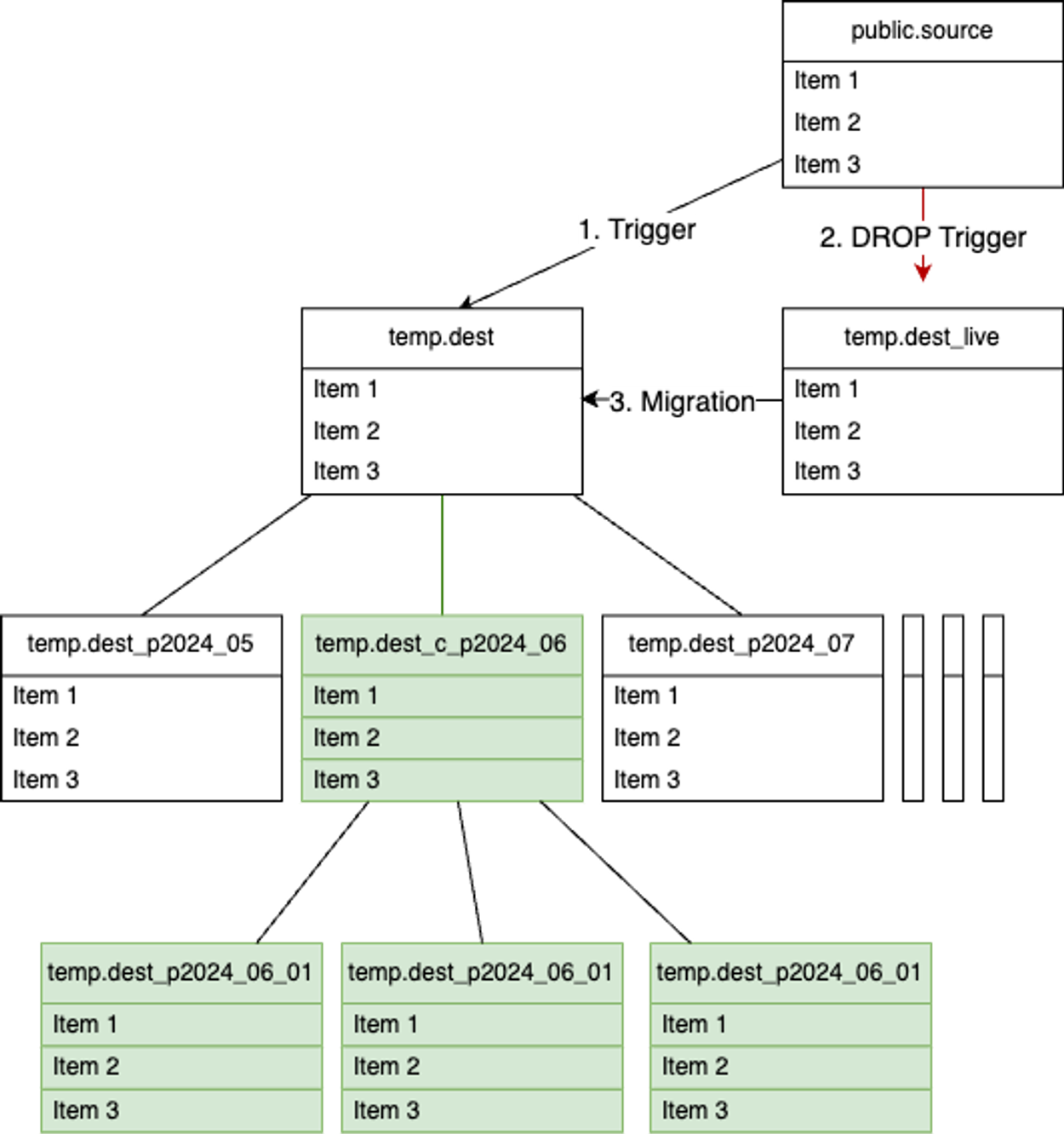
해당 작업 모두 위에 설명되어 있으므로 생략하겠다.
테이블 교체
이제 source 테이블의 모든 데이터와 실시간으로 적재되는 데이터까지 파티셔닝 된 dest 테이블에 안전하게 적재되어 있다.
마지막 작업으로 source 테이블과 dest를 교체해줘야 한다.
이때 안전하게 교체하기 위해 정기 점검 시간을 이용하여 작업을 진행했다. (작업 전에 미리 테스트는 해봐야 한다)
작업 순서는 다음과 같다.
1. 인덱서 중단
2. Trigger 제거
3. source 테이블의 schema 변경
임시로 이동시킬 schema는 wait_drop으로 지었다.
CREATE SCHEMA wait_drop;
ALTER TABLE public.source SET SCHEMA wait_drop;
4. dest 테이블을 public schema로 변경
테이블 이름이 동일하므로 그대로 이동시킨다.
ALTER TABLE temp.dest SET SCHEMA public;여기서 parent 테이블만 스키마 이동이 일어난다.
당황하지 않아도 된다. 쿼리는 문제없이 partition 테이블로 들어온다.
또한, 다른 스키마여서 권한과 관련된 문제도 생각해 볼 수 있는데 parent 테이블이 존재하는 스키마에 권한만 부여되어 있다면 문제없다.
하지만 다른 스키마에 partition 테이블이 존재하는 것은 보기에 불편하며 partman에도 문제가 발생한다.
partman config 테이블의 parent_table 이름을 수정해야 하고 파티션 테이블 모두 스키마 변경을 시켜주는 것이 좋다.
당장의 신규 테이블을 걱정하지 않아도 된다면 나중에 작업해도 된다.
5. source 테이블 제거 (optional)
정합성에 문제가 없다면 상황 봐서 테이블을 지우고 용량을 확보한다.
drop schema wait_drop;
6. 인덱서 실행
최종 모습은 다음과 같다.
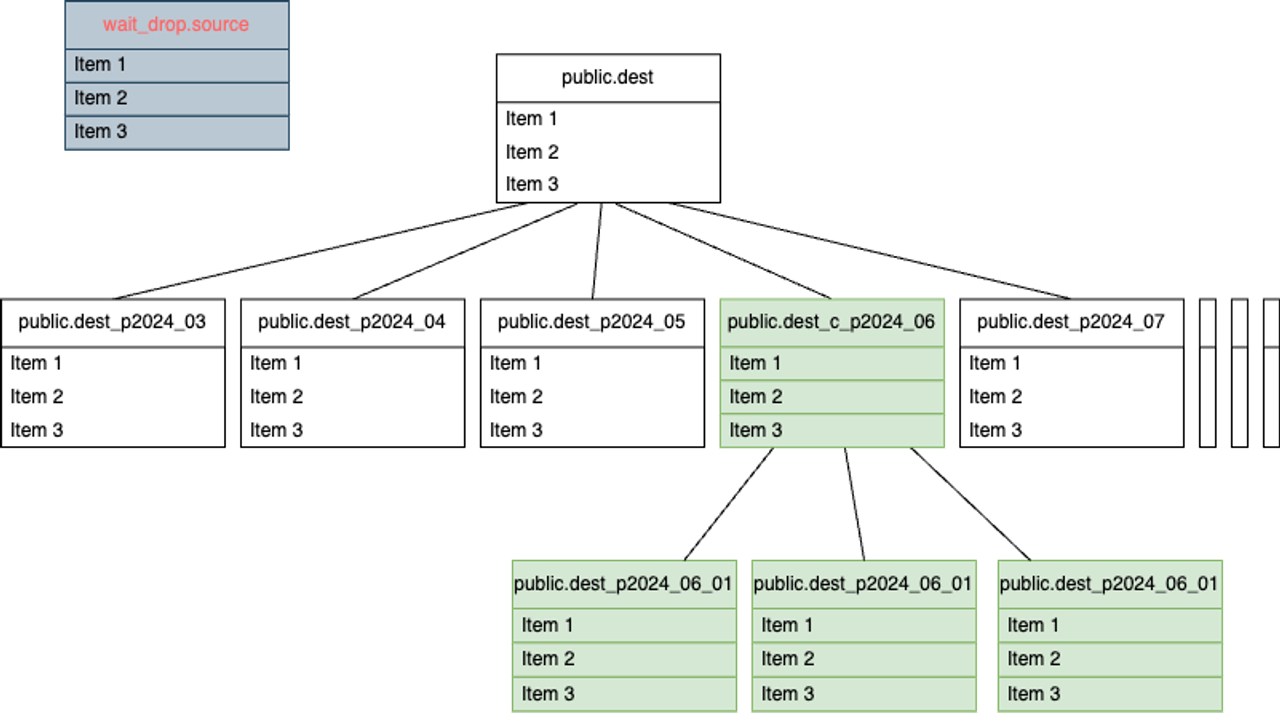
large table인 source를 dest 테이블로 대체한 모습이다.
사실상 테이블 이름은 동일하고 편의상 표기만 다르게 했다는 점 참고 바란다.
정리
글이 길어서 한번 더 정리하고자 한다.
요약
- 시스템 메모리보다 큰 테이블은 파티셔닝 권장
- 파티셔닝이 필요하다면 pg_partman 사용
- replication이 존재한다면 set logged, 없다면 set unlogged
- index 생성은 마이그레이션 이후에 생성
- 파티션 테이블이 아직 크다면 sub partitioning
- ATTACH 할 파티션 테이블이 있다면 CHECK 제약조건 추가
- random access가 적다면 CLUSTER INDEX 고려
- 더 이상 변동되지 않는 파티션 테이블에 대해 VACUUM ANALYSE 실행
기대 효과
- 블록체인 TPS가 높아져도 디비 스케일업이 필요 없을 수 있음
- VACUUM 퍼포먼스가 높아져서 데이터베이스 팽창을 줄일 수 있음
- INDEX 변경 및 생성에 유리하므로 변경되는 요구사항에 대응
- 정책에 따라 데이터를 제거하고, 용량을 확보
- 파티션 기준에 맞춰진 쿼리일 때 비용이 저렴
- 파티션 테이블별로 통계 샘플을 가질 수 있어 계획의 대한 정확도 상승
- 필요에 따라 특정 파티션 테이블의 tablespace를 빠른 SSD로 변경하거나 메모리에 캐싱
References
https://www.postgresql.org/docs/current/sql-cluster.html
https://www.postgresql.org/docs/current/routine-vacuuming.html
https://www.postgresql.org/docs/16/ddl-partitioning.html#DDL-PARTITIONING
https://blog.anayrat.info/en/2021/09/01/partitioning-use-cases-with-postgresql/
'컴퓨터 공학 (Computer Science) > 데이터베이스 (Database)' 카테고리의 다른 글
| [DB/DocumentDB] 도큐먼트 데이터베이스와 MongoDB (2) | 2022.12.14 |
|---|---|
| [DB/TSDB] 시계열 데이터베이스와 influxDB (4) | 2022.11.29 |

